图 a
图 a
df = pd.read_excel("历年世界杯各国数据.xlsx")
![]()
print(df)
则方框处可选代码是 (按数据处理先后顺序填序号)。
①df = df.groupby("所属大洲")
②df = df[:3]
③df = df.sort_values("进球数", ascending=False)
④df = df[df["所属大洲"]=="非洲"]
⑤df = df["非洲"]
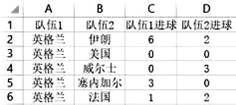 图 b
图 b
df1 = pd.read_excel("历年世界杯各国数据.xlsx")
df2 = pd.read_excel("英格兰.xlsx")
for i in range(len(df1)):
if df1.at[i, "球队"]=="英格兰":
break
for line in df2.values:
goal = line[2]; lost = line[3]
if goal>lost:
df1.at[index, "胜"] += 1
elif
goal<lost:
df1.at[index, "负"] += 1
else:
df1.at[index, "平"] += 1
df1.at[index, "进球数"] += goal
df1.at[index, "失球数"] += lost
df1.at[index, "净胜球"] += goal - lost
df1.to_excel("(new)历年世界杯各国数据.xlsx", index=False) #去除索引保存文件
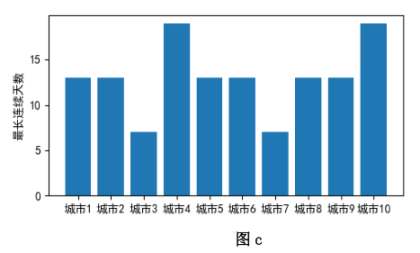
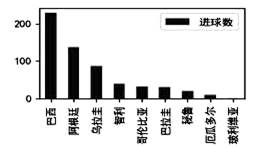 图 c
图 c
df1 = pd.read_excel("(new)历年世界杯各国数据.xlsx")
df1 = df1.sort_values("进球数",ascending=False) #①
df1 = df1[df1["所属大洲"]=="南美洲"]
df1 = df1[["球队", "进球数"]] #②
df1.plot.bar(x="球队", y="进球数") #③
plt.show() #④

def avg(filename):
df=pd.read_csv(filename)
df1=df[df.columns[2:]] # 取类型及其后的所有列
g=df1.groupby( ① ,as_index=False).mean()
return ②
划线②处应填入的代码为(单选,填字母)。
A.df[df.类型=='AQI'] B.df1.AQI C.g.AQI D.g[g.类型=='AQI']
import pandas as pd
import matplotlib.pyplot as plt
n=10 #城市个数
count=[0]*n
daymax=[0]*n
for i in range(1,31):
day=str(i)
if len(day)<2:
day='0'+str(i)
daydata='202204'+day+'.csv'
dayaqi=avg(daydata)
city=dayaqi.columns[1:n+1]
for j in range(n):
t=city[j]
if dayaqi.at[0,t] <= 100:
else:
if count[j]>daymax[j]:
daymax[j]=count[j]
count[j]=0
for k in range(n):
if count[k]>daymax[k]:
print(daymax)
plt.figure(figsize=(12,4))
x=
y=daymax
plt.bar(x,y)
plt.show()
小洪用Python编写投票系统,第一轮投票数据经处理后,保存在"vote2023.xlsx"文件中,部分数据如图a所示,请回答下列问题。
 图 a
图 a
def check(datafile):
df=pd.read_excel(datafile)
df["票数"]=df.sum(axis=1)-df["序号"] # 统计每张选票的票选数
df1=df[ ]
return df1
划线处应填入的代码为 (单选,填字母)。
df=check("vote2023.xlsx")
df2=df.drop(["序号","票数"],axis=1) # 删除序号列、票数列
s=[];st=[]
for i in df2.columns:
s.append([i,int(df2[i].sum())])
#统计每人选票数,格式如['李彤',377]
for i in range(len(s)):
num=1
for j in range(len(s)):
if :
num+=1
if :
st.append(s[i]) # 存储前三名数据
for i in range(len(st)):
plt.bar(st[i][0], ) # 绘制柱形图
# 设置图表的标题及图例数据并显示图表,代码略
 图 b
图 b
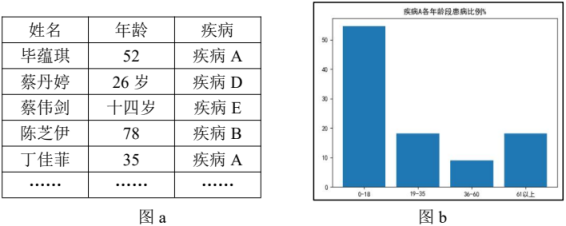
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel('data.xlsx')
tp = input('请输入疾病类型:')
df1 = # 筛选 tp 疾病的数据
count = [0] * 4
for i in range(len(df1)):
age = df.at[i, "年龄"]
if:
count[0] += 1
elif age <= 35:
count[1] += 1
elif age <= 60:
count[2] += 1
else:
count[3] += 1
x = ['0-18', '19-35', '36-60', '61 以上']
y = []
for i in range(4):
y.append
plt.bar(x, y) # 显示不同年龄段患该病的人数百分比
# 设置图表其他参数,代码略
plt.show()
def get_head10(df, age):
![]()
return df.疾病.head(10)
print(get_head10(df, 61))
上述程序段中方框处可选代码为:
①df = df.sort_values("年龄", ascending=False)
②df = df[df.年龄 >= age]
③df = df.groupby("疾病", as_index=False).count()
则加框处应填代码的顺序依次为( )(单选,填字母)
 图 a
图 a
 图b
图b
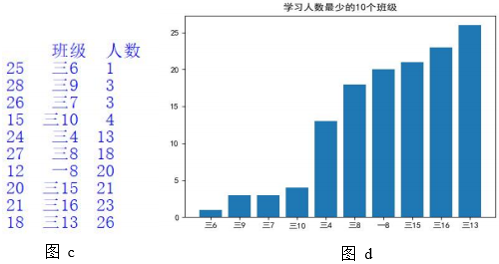
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
| df = pd.read_excel("qndxx.xlsx") | |
| dfl = df.① | #按班级列进行分组 |
| df2=df1.学校.count( ) | #统计各班级学习人数 |
| df2=df2.rename(columns= {"学校":"人数"}) | |
| df3=df2.sort_values ("人数",ascending=True).head(10) print(df3) | #筛选前 10 名 |
| ② | #绘制柱形图 |
| plt.title("学习人数最少的 10 个班级") | #设置图表标题 |
| plt.show () |
|
图 a |
图 b |
统计全年每月降水天数(当日总降水量大于 0 即计入降水天数),编写 Python 程序,回答下列问题:
import pandas as pd
df=pd.read_excel ("weather.xlsx")
df1=
print(df1)
import matplotlib.pyplot as plt
plt.rcParams['font.family']='SimHei' #设置图表中的中文字体
days=[31,28,31,30,31,30,31,31,30,31,30,31] #2022 年每月天数
rain_days=[0]*12
begin=0
for m in range(12):
for d in range(begin, ):
if df1.at[d,"降水量"]>0:
begin+=days[m]
x=[i+1 for i in range(12)]
y=rain_days
plt.bar ( , label="降水天数") plt.xticks(x) #设置横坐标刻度
plt.legend()
plt.show ()
 图 c
图 c
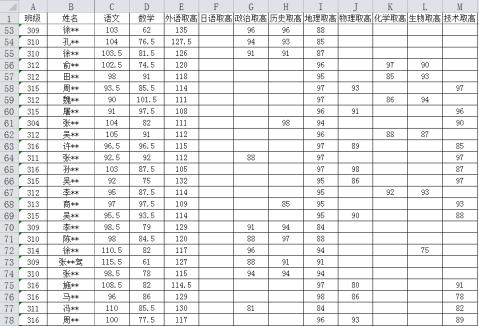
import pandas as pd #引入pandas 模块
import matplotlib.pyplot as plt #引入matplotlib 的pyplot 子库
df=pd. ('cj.xlsx') #读取"cj.xlsx"文件中的数据,创建DataFrame 对象df
# 若要筛选本次考试数学分数超过120分且技术分数到达88分及以上的学生并输出他们的考试情况 (df1中保存筛选结果,提示: 多条件筛选时,与(and) 关系用“&”连接, 或(or) 关系用“|”连接)
df1 = (单选, 填字母)
print (df1)
A.df[(df["数学"] >= 120 )&(df["技术取高"] >= 88)]
B.df[(df["数学"] > 120 )&(df["技术取高"] >= 88)]
C.df[(df["数学"] > 120 ) | (df["技术取高"] >= 88)]
D.df[(df["数学"] >= 120 ) | (df["技术取高"] > 88)]
# 若要了解该校参加该次考试选考各科的选课人数,请完善下面的代码。
for km in df.columns[6:13]:
renshu = ;
print("选",km,"的人数为:",renshu)
# 想要了解该校技术班级数学科的平均分,并绘制一个图表, 针对各班数学平均分进行比较分析 df2 = df.groupby("班级",as_index = False).mean()
df3 = df2.sort_values("数学", ) # 通过排序使得按平均分降序排序并存储在 df3 中 plt.bar (df3.班级, df3.数学 )
plt.title("班级数学平均分比较")
plt.xlabel("班级")
plt.ylabel("数学平均分")
plt.show ()
|
图 a |
图 b |
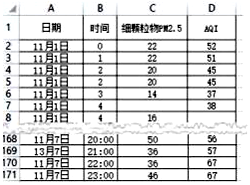
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["Simhei"]
df=pd.read_excel ("空气质量.xlsx")
df=df.head(24*7)
df_ave=df.groupby("日期",as_index=False). #日平均 AQI df_sort=df_ave.sort_values("AQI",ascending= )
plt.bar( ,df_sort["AQI"],label="日均空气质量指数")
plt.legend( )
plt.xlabel("日期")
plt.ylabel("AQI 值")
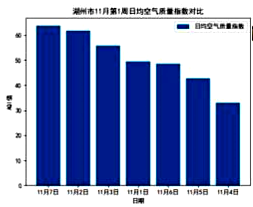
plt.title("湖州市 11 月第 1 周日均空气质量指数对比")
plt.show ()
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请