
|
图b |
图c |
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("data.xlsx") #读取Excel文件中的数据
df["借阅次数"] = [0]*len(df) #插入新的列用来保存各类书籍的借阅次数
df1 = df.groupby("书籍类别", as_index = False).借阅次数. ①
df2 = df1.sort_values("借阅次数", ascending = False ).head(3)
x = df2["书籍类别"]
y = ②
plt.title("本周最受欢迎图书前3类") #设置图表标题
plt.bar(x, y) #绘制柱形图
plt.show()
|
图 a |
图 b |
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel("PM2.5.xlsx")
# cities 保存所有地区名称,这里仅演示部分数据
cities = ["安吉县", "淳安县", "慈溪市", "杭州市", "湖州市"]
for city in cities:
dfc = ①
dfc.to_excel(city + ".xlsx", index=False) # 输出文件结果示例如图b所示
那么划线部分语句可以是 ;
df = pd.read_excel("PM2.5.xlsx")
# 删除“地区编码”、“指标名称”、“计量单位”数据列
df = df.drop(["指标名称", "地区编码", "计量单位"], axis= ② )
# 同一个地市取 PM2.5 浓度最高的值
dfg = ③
# 按 PM2.5 的值升序排序
dfg = dfg.sort_values("PM2.5", ascending=True)
# 输出排序后的最后五行结果
print(dfg.tail())
|
图 c |
图 d |
df2 = pd.concat([dfg.head(5), dfg.tail(5)]) # 合并两个对象成为新的 DataFrame 对象
plt.rcParams['font.sans-serif']=['KaiTi','SimHei','FangSong'] # 设置图表字体
plt.figure(figsize=(8,4))
plt.title("部分县市 PM2.5 浓度对比")
plt.xlabel("PM2.5 浓度值")
plt.bar( , df2["PM2.5"], color="orange")
for i in range(len(df2)):
x = df2.index[i]
y =
# text()方法可以绘制数据标签,语法:text(横坐标,纵坐标,显示内容)
plt.text(x, y, '%d' % y)
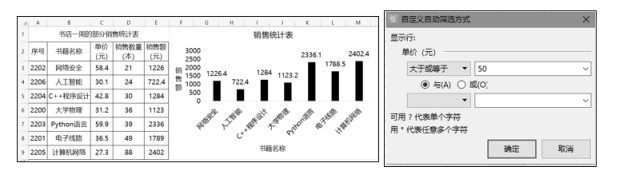
②选用以下哪种图最适合。

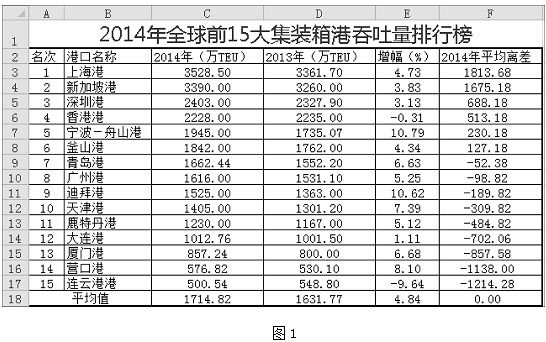
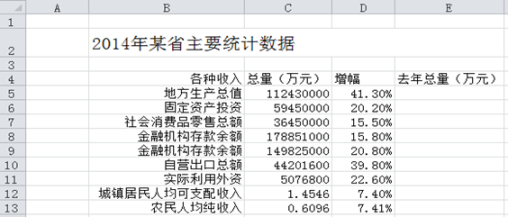 图1
图1
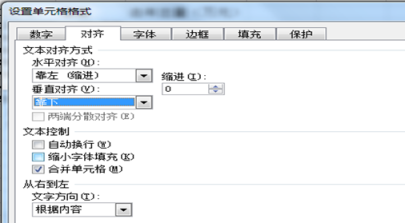 图2
图2

图3
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请