


信息社团的两个小组收集了不同年级学生点餐及菜品评分的数据,数据集合用“数据集A”与“数据集B”来表示,分别存储在“数据集A.xlsx”与“数据集B.xlsx”文件中,如1图、2图所示:
|
1 图 数据集 A.xlsx
2 图 数据集 B.xlsx |
①将“数据集B”中的“★”评价转换为数值评分
②舍弃“数据集B”中“年级”列数据
③修改“数据集A”中“序号”列数据,从1开始递增
④合并“数据集B”至“数据集A”
下列选项中,操作顺序正确的是( )(单选,填字母)
|
|
编写Python程序实现上述功能:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_excel ("数据集 A.xlsx")
df = ![]()
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
plt.figure(figsize=(15,5))
x=df.菜品名称
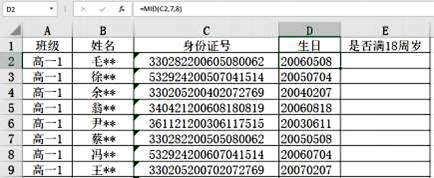
y= _________________
plt.bar (x,y)
plt.title("菜品评分情况")
plt.xlabel("菜品名称")
plt.ylabel("平均评分")
for i,j in zip(x,y): #设置图表标签
plt.text(i,j+0.05,'%0.2f'%j,ha='center')
plt.show ()
加框处代码应为( )(单选,填字母)
高一 1|谢乐|340421200606455914
高一 1|岑新奇|330282200407301529
| 说明:split( )函数实例。 x=“高一 1|岑新奇|330282200407301529” y=x.spilt(“| ”) 得到的 y 中存放的数据是: [“高一 1”,“岑新奇”,“330282200407301529”] |
f=open("stu_info.txt","r",encoding="utf8")
namelist=[ ] #存放年满18周岁的学生名单
for line in f.readlines():
stu=line.split("|")
birth=
if birth<="20041231":
namelist.append()
print(namelist)
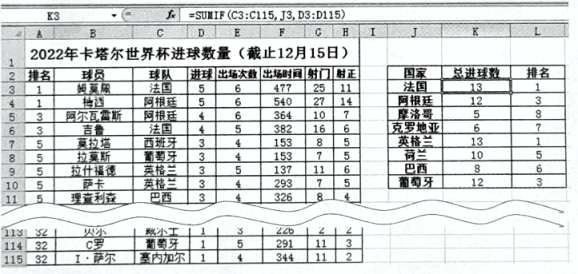
已知D7中的数据是通过D2单元格自动填充得到,D2中的公式是=MID(C2, 7, 8),则D7中的公式应该是。若E2中的公式是=D2<“20041231”,回车后,E2单元格中显示的结果是。(单选,填字母。A .True B .False C .“20041231”)随后对E列进行筛选就可以得到年满18周岁的名单。
①执行筛选后,不满足条件的数据将被删除。
②去除筛选标志后,原先不显示的数据仍然不会显示。
③利用自动筛选,能将满足条件的最大的15%的数据列出来。
④在“姓名”列数据中设置文本筛选,包含“李”,可以只显示所有姓李的人的记录。
⑤自定义筛选最多只允许定义两个条件。
![]()
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请


 3 图
3 图