|
图 a |
图 b |
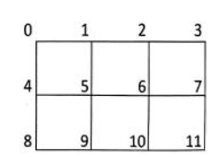
编写函数init,根据横向和纵向的正方形数量,返回所有顶点及其所有的相邻顶点数据。完善程序,在划线处填入合适的代码。
def init(m,n):
tot=(m+1)*(n+1) #顶点总数
lst=[[] for i in range(tot)]
for i in range(tot):
if i>m:
lst[i].append(i-m- 1)
if i<(m+1)*n:
lst[i].append(i+m+1)
if i%(m+1) != 0:
lst[i].append(i- 1)
if i%(m+1) != m:
return lst
 图 c
图 c
编写函数print_path,输出所有的最短路径。完善程序,在划线处填入合适的代码。
def print_path(x,path,length): #为起点编号,length为Path中有效元素个数。
cnt=0
for i in range(length):
if path[i][0] == x:
cnt+= 1
s="最短路径"+str(cnt)+":"
v=path[i]
while :
s=s+str(v[0])+","
v=path[v[2]]
s=s+str(v[0])+" 。"
print(s)

m=3 #横向正方形数量
n=2 #纵向正方形数量
mtx=init(m,n)
x=int(input("请输入起点:"))
y=int(input("请输入终点:"))
path=[[] for i in range(30)]
passed=[False]*len(mtx) #保存顶点是否已途经
dis=0
head=0
tail=0
path[tail]=[y,0,- 1]
tail+= 1
passed[y]=True
while not found:
dis+= 1
pass_dis=[False]*len(mtx)
tmp=tail
for i in range(head,tail):
v=path[i]
for d in mtx[v[0]]:
if not passed[d]:
path[tail]=
tail+= 1
pass_dis[d]=True
if d == x:
found=True
head=tmp
for i in range(len(mtx)): #标记已途经的顶点
if :
passed[i]=True
#输出结果
print_path(x,path,tail)
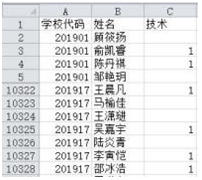
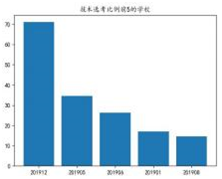
import pandas as pd
import matplotlib.pyplot as plt
#图表支持中文字体显示,代码略
df= pd.read_excel("jsxk.xls",dtype={'学校代码':'string'}) #学校代码列为字符串
df1 = df.groupby(" ", as_index=False).count() #按学校统计人数
df1 = df1.rename(columns={'姓名':'学生总数'})#重命名列
df1['技术比例'] = round(/df1['学生总数']* 100,2)
df1 = df1.sort_values('技术比例',ascending=False).head(5)
plt.title('技术选考比例前 5 的学校')
plt.bar( )
plt.show()
def zdygroupby(1st):
dic = {}
for row in lst:
if row[2] == 1:
if :
dic[row[0]]=1
else:
dic[row[0]]+= 1
def judge(a, b):
n=len(a) ;st=[- 1]*n
top-= 1; i=j=0
while i<n:
top+= 1
①
i+= 1
while top> - 1 and ② :
top-= 1
j+= 1
return top==- 1
from random import shuffle
a=[1,2,3,4, 5]
b=[1,2, 3, 4, 5]
shuffle (b) #将序列 b 的元素随机排序
if judge(a, b):
print (b,'是' ,a,' 的出栈序列')
else:
print (b,'不是' ,a,' 的出栈序列')
程序运行结果如图所示。划线处应填写的语句是( )

|
图 1 |
图 2 |
| def sort(): for i in range(3): for j in range(3,i,- 1): if waitlist[index[j]][1] > waitlist[index[j - 1]][1]: index[j], index[j - 1] = index[j - 1], index[j] if waitlist[index[j]][1]==0: return j return 4 waitlist=[[3,6],[4,0],[1,2],[2,4]] # "咖啡 0" 的批量制作时间为 3 分钟,目前待做量为 6,以此类推 q=[[6, 0, 2, 4], [1, 18, 0, 2], [2, 1, 2, 1], [0, 1, 0, 5],…… #如图 1,代码略 #q 保存订单流,第一个订单[6,0,2,4]作为初始订单已计入 waitlist index=[0,1,2,3] y=sort() lnk=[- 1]*4 for i in range(y- 1): #创建降序链表 lnk[index[i]]=index[i+1] p=lnk_h=index[0] print("请制作咖啡"+str(p)) waitlist[p][1]=0 #咖啡 p 进入制作,待做数量回 0 |
| defenqueue(order): #order 是一个订单,例如[1,2,0,3] global lnk_h flag.append([0,0,0,0]) #新订单 4 种咖啡未完成 for i in range(4): if waitlist[i][1]==0: f=False if order[i]==0: continue waitlist[i][1]+=order[i] #将订单 order 中的咖啡 i 累加到待制作数量中 cur=lnk_h while cur!=- 1 and waitlist[i][1]<waitlist[cur][1]: pr,cur=cur,lnk[cur] if cur!=i: tmp = lnk[i] lnk[i]=cur if cur==lnk_h: lnk_h=i else: lnk[pr]=i if f: while cur!=i: pr,cur=cur, lnk[cur]
def nextfood(qhead,qtail): #找到下一次要做的咖啡 global lnk_h cur=lnk_h while : pr,cur=cur,lnk[cur] if cur==lnk_h: lnk_h=lnk[lnk_h] elif cur==- 1: return – 1 else: lnk[pr]=lnk[cur] waitlist[cur][1]=0 for i in range( ): if q[i][cur]!=0: flag[i][cur] = 1 return cur qhead,qtail=0,1 order=q[qhead] flag=[[1,0,0,0]] #flag[i][j]=1 标记"订单 i" 中的"咖啡j" 已经在做或已经做完。 lnk_h, time =lnk[lnk_h],0 while True: time=(time+1)%waitlist[p][0] if qtail<len(q): enqueue(q[qtail]) #接新订单 qtail+=1 if time==0: while qhead<qtail- 1 and sum(flag[qhead])+q[qhead].count(0)==4: #订单完成时 qhead+=1 order=q[qhead] p=nextfood(qhead,qtail) if p == - 1 : break print("请制作咖啡"+str(p)) |
| def fun(k): if k==1 : return "1" elifk%2==0: return fun(k- 1)+str(k%2) else: returnstr(k%2)+fun(k- 1) |
执行语句 s=fun(5) ,则 s 的值为( )
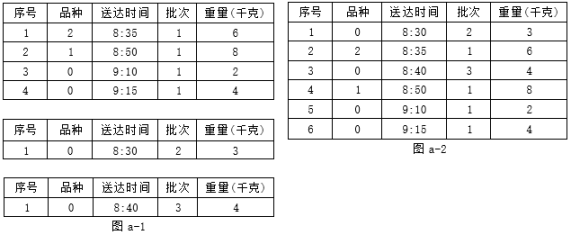

请回答下列问题:
def data_sort(lst):
for i in range(n- 1):
for j in range(n- 1,i,- 1):
if lst [j][2]< lst [j- 1][2]:
lst [j], lst [j- 1]= lst [j- 1], lst [j]
lst[i][0]=i+1
return lst
执行上述代码后, (填写:能/不能)正确得到如图 a-2 中的数据。
def pack(k): #对品种 k已送达待打包的物品按重量由大到小输出
#部分代码略
p=b[k][1]
num+= 1
print("第"+str(num)+"个包裹中品种为"+str(k)+" ,各物品的序号依次是:",end=" ")
while p!=- 1:
print(data[p][0],end=",")
p=x[p]
print()
'''
合并后排序得到 n 件物品的数据存储在数组 data 中并输出,包裹最大承受最大重量为 m 千克。 物品品种的数量是 sn ,代码略
'''
b=[[0,- 1] for i in range(sn)]
x=[- 1 for i in range(n)]
num=0
for i in range(n):
k=data[i][1]
if b[k][0]+data[i][4]>m :
pack(k)
b[k]=[0,- 1]
p=
if p==- 1:
b[k][1]=i
else:
if data[i][4]>data[p][4]:
b[k][1]=i
else:
q=- 1
while :
q=p
p=x[p]
x[q]=i
x[i]=p
b[k][0]+=data[i][4]
#重量不足 m 的品种,按各品种依次装入包裹
for i in range(sn):
if b[i][1]!=- 1:
pack(i)
def fi(s,b,e):
income=0
i=b
while i<=e:
if s[i]=="A":
income+=
i+=2
elif s[i]=="B":
income+=int(s[i+1:i+3])*300
i+=3
elif s[i]=="C":
income+=int(s[i+1:i+3])*200
i+=3
return income
s=input("请输入订单码:")
flag=False
for i in range(len(s)):
if s[i]=="-" and not flag:
flag=True
elif s[i]=="-":
q=i
elif s[i]==",":
e=i
total=fi(s,p+1,e- 1)
total+=fi(s, ,len(s)- 1)
print(total)
deff(x):
if x==1:
return 2
else:
return f(x- 1)**2
y=f(3)
print(y)
执行该程序段后,输出的结果是( )
方法1:设置左右两个索引,从两边往中间逐次判断。补充完整代码。
def fun_1(s):
L=0
R=
while :
if s[L]!=s[R]:
return False #函数返回False并退出
L=L+1
return True #函数返回True并退出
方法2:只设置左边一个索引,利用对应关系获取右边索引位置。按提示要求补充完整代码。
def fun_2(s):
n=len(s)
for i in range(): #请写出最小的遍历区间值,即不可写n
if :
return False
return True
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请