

A | 00001 | B | 00010 | C | 00011 | D | 00100 | E | 00101 | F | 00110 | G | 00111 |
H | 01000 | I | 01001 | J | 01010 | K | 01011 | L | 01100 | M | 01101 | N | 01110 |
O | 01111 | P | 10000 | Q | 10001 | R | 10010 | S | 10011 | T | 10100 | U | 10101 |
V | 10110 | W | 10111 | X | 11000 | Y | 11001 | Z | 11010 |
小明使用该编码对由大写字母组成的明文字符串进行加密,加密算法如下:
l依次将明文中每个字符转换为其对应的二进制编码;
l依次将密钥中每个字符转换为其对应的二进制编码;
l依次取出密钥的每个二进制位与原文的二进制位进行异或运算(若密钥长度不够,则循环重复使用),得到的结果即为密文编码;
l二进制位异或运算原则:1![]() 1=0,0
1=0,0![]() 0=0,1
0=0,1![]() 0=1,0
0=1,0![]() 1=1
1=1
例如,明文:HELLO,密钥:ZHE,则按上述方式进行加密:
明文字符 | H | E | L | L | O |
密钥字符 | Z | H | E | Z | H |
明文编码 | 01000 | 00101 | 01100 | 01100 | 01111 |
密钥编码 | 11010 | 01000 | 00101 | 11010 | 01000 |
密文编码 | 10010 | 01101 | 01001 | 10110 | 00111 |
def ctob(c): # 将一个字符转换为其对应的5位二进制编码
n =
ans = ""
for i in range(5):
r =
n = n // 2
ans = str(r) + ans
return ans
def xor(s1, s2): # 将二进制数s1和s2进行异或运算
ans = ""
for i in range(len(s1)):
if :
ans += "0"
else:
ans += "1"
return ans
s = input("请输入明文(大写字母):")
key = input("请输入密钥(大写字母):")
ans = ""
for i in range(len(s)):
s1 = ctob(s[i])
k =
s2 = ctob(key[k])
b = xor(s1, s2)
ans = ans + b
print("密文编码为:", ans)

def isprime(n): #判断n是不是素数
for i in range(![]() ):
):
if n%i==0:
else:
return True
def strsum(word): #统计单词的字母值总和
dic={"a":1,"b":2,"c":3,"d":4,"e":5,"f":6,"g":7,"h":8,"i":9,"j":10,
"k":11,"l":12,"m":13,"n":14,"o":15,"p":16,"q":17,"r":18,"s":19,
"t":20,"u":21,"v":22,"w":23,"x":24,"y":25,"z":26}
n=0
for ch in word:
return n
word=input("请输入一个单词:")
s=strsum(word)
if flag:
print("这是一个素单词")
else:
print("这不是一个素单词")
def dele(a, head):
pre=head; p=a[head][1]
while p!=-1:
q=head
flag=False
|
if a[q][0]==a[p][0]:
|
p=a[p][1]
flag=True
break
q=a[q][1]
if not flag:
pre=p;
p=a[p][1]
a=[[0, 3], [1, 2], [1, 4], [0, 1], [0, 5], [2, -1]]
dele(a, 0)
①q!=-1 ②q!=p ③a[pre][1]=a[p][1] ④a[pre][1]=a[q][1]
方框中填入的正确代码依次为( )
 图a
图a
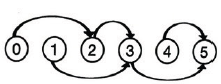
为了梳理产品组件的组装顺序,并计算所有组件安装完成所需的最短时间,编写程序模拟组装过程:先同时组装前置总数为0的组件,完成后更新每个组件的前置总数,再重复以上步骤,直至所有组件安装完毕,程序运行结果如下图b所示,请回答下列问题:
 图b
图b
Def cal(a, n):
pre=[0]*n
s=[[0 for i in range(n)] for j in range(n)] #创建n×n的二维数组s,元素初始值为0
for i in range(len(a)):
x, y=a[i][0], a[i][1]
s[x][y]=1
pre[y]=
return pre, s
def proc(n, s, pre):
head=tail=0
que=[0]*n
for I in range(n):
if pre[i]==0:
que[tail]=i
tail+=1
while ![]() :
:
x=que[head]
head+=1
for i in range(n):
if s[x][i]==1:
pre[i]-=1
if pre[i]==0:
que[tail]=i
tail+=1
v[i]=max(v[i], )
return v
"""
组装编号0~n-1的单个组件所需时间存入t列表,组件前置关系存入a列表,如第15题图a所需时间t=[2, 5, 2, 4, 3, 5];a=[[0, 2], [2, 3], [1, 3], [3, 5], [3, 4]]
"""
n=len(t)
print(’编号为0~’+str(n-1)+’的组件组装所需单位时间分别为:’, t)
v=t[:]
pre, s=cal(a, n)
v=proc(n, s, pre)
data=[0]*n
result=[i for I in range(n)] #创建列表result=[0,1,2,……,n-1]
for i in range(n):
data[i]=v[i]-t[i] #data[i]表示组件i开始安装时间
for i in range(n-1): #按组件开始安装时间升序排序,开始安装时间相同时按组件序号升序
for j in range(n-1-i):
if data[result[j]]>data[result[j+1]]:
print(‘组件组装顺序:’, result, ‘, 安装完成所需最短时间:’, max(v))
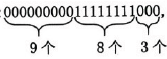 ,压缩结果为“0, 9, 8, 3”(用逗号分隔)
,压缩结果为“0, 9, 8, 3”(用逗号分隔)Def jys(s):
d={"1":"0","0":"1"}
ns=""; p=s[0]; i=2
while i<n:
num=0
while :
num=num*10+int(s[i])
i+=1
i+=1
for j in range(num):
p=d[p]
return ns
def fun(x, i):
if x<i:
return i
elif x%i==0:
return x
else:
return fun(x-i, i+1)
执行语句k=fun(37, 3)后,k的值为( )
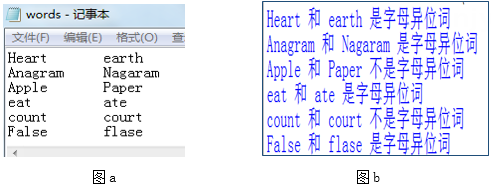
程序代码如下,程序运行后输出结果部分界面如图b所示,请回答下列问题。
def change(x): #将字母都转换为小写字母
y=""
for k in x:
if "A"<=k<="Z":
k=
y+=k
return y
def fs(m,n):
cnt=[0]*26
for i in range(len(m)):
ch=ord(m[i])
for i in range(len(n)):
ch=ord(n[i])
cnt[ch-ord("a")]-=1
return cnt
file=open("words.txt","r") #以只读的方式打开文件
text=[];s1=s2=""
line=file.readline() #从文件中读取一行
while line: #当 line 非空(从文件中读取到数据)
line=line.strip() #把末尾的'\n'去掉
text.append(line.split())#方法是把空白字符去掉,把line变成包含2个单词的列表line=file.readline()
file.close()
for i in range(num):
s1=text[i][0]
s2=text[i][1]
c=
j=0
while j<len(c):
if c[j]!=0:
print(s1,"和",s2,"不是字母异位词")
break
j+=1
else: # 在循环正常结束后执行
print(s1,"和",s2,"是字母异位词")
def readname(): #读取某个文件夹内所有文件的文件名
filepath="pics//"
#读取到的文件名以字符串的形式,作为元素存储在列表 allname 中
allname=os.listdir(filepath)
#os.listdir()用于返回指定的文件夹包含的文件或文件夹的名字的列表
return
def checkname(name):
s=""
for i in name:
if i=="+" or i=="-":
s+="&"
else:
s=s[:-5] #去掉后四位,即去掉后缀名".docx"
return s
name=readname()
student=["王俊凯","王源","张明","赵祖一","吴天","顾玲玲","方奔奔","张强"] yes=[];no=[];s=0;result={}
for item in name:
item=checkname(item)
yes.append(stu) #将学生的姓名加入列表
s=s+1
for m in student:
if:
no.append(m)
result[" 应 提 交 人 数 :"]=len(student)
result[" 已 提 交 人 数 :"]= ▲
result["已提交的同学:"]=yes
result["还未提交的同学:"]=no
print(result)
划线处可以填入的代码是 (多选,填字母)
from math import *
def isPrime(x): # 判断是否为素数
i = 2
while ![]() :
:
if x % i == 0:
return ①
i += 1
return True
count = 0
for p in range(2, 50): # 判断否为梅森素数
if ② :
m = ③
if isPrime(m) == True:
print(m)
count += 1
print("2的50次方减1以内的梅森素数共有:" + ④ + "个")
① ② ③ ④
from math import *
def dist(x1, y1, x2, y2):
length = sqrt((int(x1) - int(x2))**2 + ① )
return length
a = input("请输入各点的坐标:") # 如“2,3,4,5”则表示坐标点(2,3)和(4,5)
b = a.split(",")
if len(b) % 2 != 0:
print("输入的坐标有误!")
else:
s = 0
for i in range(0, ② , 2):
s = s + ③
print("折线的长度为:", s)
A.程序输出正确的折线长度
B.输入的坐标有误!
C.程序运行出错!
① ② ③
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请
