

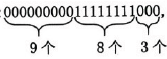
 ,压缩结果为“0, 9, 8, 3”(用逗号分隔)
,压缩结果为“0, 9, 8, 3”(用逗号分隔)Def jys(s):
d={"1":"0","0":"1"}
ns=""; p=s[0]; i=2
while i<n:
num=0
while :
num=num*10+int(s[i])
i+=1
i+=1
for j in range(num):
p=d[p]
return ns
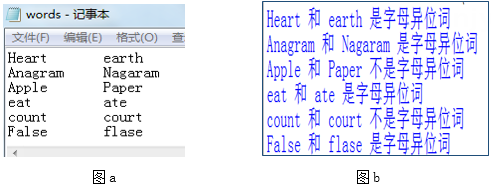
程序代码如下,程序运行后输出结果部分界面如图b所示,请回答下列问题。
def change(x): #将字母都转换为小写字母
y=""
for k in x:
if "A"<=k<="Z":
k=
y+=k
return y
def fs(m,n):
cnt=[0]*26
for i in range(len(m)):
ch=ord(m[i])
for i in range(len(n)):
ch=ord(n[i])
cnt[ch-ord("a")]-=1
return cnt
file=open("words.txt","r") #以只读的方式打开文件
text=[];s1=s2=""
line=file.readline() #从文件中读取一行
while line: #当 line 非空(从文件中读取到数据)
line=line.strip() #把末尾的'\n'去掉
text.append(line.split())#方法是把空白字符去掉,把line变成包含2个单词的列表line=file.readline()
file.close()
for i in range(num):
s1=text[i][0]
s2=text[i][1]
c=
j=0
while j<len(c):
if c[j]!=0:
print(s1,"和",s2,"不是字母异位词")
break
j+=1
else: # 在循环正常结束后执行
print(s1,"和",s2,"是字母异位词")
def readname(): #读取某个文件夹内所有文件的文件名
filepath="pics//"
#读取到的文件名以字符串的形式,作为元素存储在列表 allname 中
allname=os.listdir(filepath)
#os.listdir()用于返回指定的文件夹包含的文件或文件夹的名字的列表
return
def checkname(name):
s=""
for i in name:
if i=="+" or i=="-":
s+="&"
else:
s=s[:-5] #去掉后四位,即去掉后缀名".docx"
return s
name=readname()
student=["王俊凯","王源","张明","赵祖一","吴天","顾玲玲","方奔奔","张强"] yes=[];no=[];s=0;result={}
for item in name:
item=checkname(item)
yes.append(stu) #将学生的姓名加入列表
s=s+1
for m in student:
if:
no.append(m)
result[" 应 提 交 人 数 :"]=len(student)
result[" 已 提 交 人 数 :"]= ▲
result["已提交的同学:"]=yes
result["还未提交的同学:"]=no
print(result)
划线处可以填入的代码是 (多选,填字母)
from math import *
def isPrime(x): # 判断是否为素数
i = 2
while ![]() :
:
if x % i == 0:
return ①
i += 1
return True
count = 0
for p in range(2, 50): # 判断否为梅森素数
if ② :
m = ③
if isPrime(m) == True:
print(m)
count += 1
print("2的50次方减1以内的梅森素数共有:" + ④ + "个")
① ② ③ ④
from math import *
def dist(x1, y1, x2, y2):
length = sqrt((int(x1) - int(x2))**2 + ① )
return length
a = input("请输入各点的坐标:") # 如“2,3,4,5”则表示坐标点(2,3)和(4,5)
b = a.split(",")
if len(b) % 2 != 0:
print("输入的坐标有误!")
else:
s = 0
for i in range(0, ② , 2):
s = s + ③
print("折线的长度为:", s)
A.程序输出正确的折线长度
B.输入的坐标有误!
C.程序运行出错!
① ② ③
def tob(n)
if n=0:
return "*
else:
return tob(n//2)+str(1-n%2)
执行语句s=tob(10) 后,s的值为( )
①当天08:00之前完成签到的患者,按照挂号顺序从小到大排队就诊;
②08:00之后签到的患者,按照挂号的序号从小到大的次序插入候诊队伍中;
③队伍中前3名患者(包括正在就诊患者)视为已进入待诊状态,插队的患者只能插到这3 名待诊患者后的队伍中。
假设医生从08:00开始叫号就诊,对每位患者的诊断时间均为3分钟,忽略相邻患者就 诊的时间间隔。编写程序实现以下功能:若有患者签到,则根据规则更新候诊队伍;医生每 完成一名患者的诊断,电子屏幕上按顺序显示待诊的患者姓名和每个患者预计就诊的时间。
| 姓名 | 挂号序号 | 签到时间 |
| A | 3 | 07:47:03 |
| B | 1 | 07:51:12 |
| C | 6 | 07:55:32 |
| D | 4 | 07:57:10 |
| E | 8 | 07:59:52 |
| F | 2 | 08:02:07 |
则患者 F的预计就诊时间为 (格式如08:07:20)。
def init(lst): #构建8点前签到的候诊队伍
i=0;n=len(lst)
while i<n-1:
k=i;i=n-1
for j in range(n-1,k,-1):
if lst[i][1]<lst[j-1][1]:
lst[j],Ist[j-1]=Ist[j-1],Ist[j]
____▲____
for i in range(n):
lst[i][2]=180*i
lst[i].append(i+1)
lst[n-1][3]=-1
#修改时间格式,每位患者诊断时间为3分钟
#尾结点指针域处理,如[’E’,8,720,-1]
程序划线处的代码是 (单选,填字母)
def gs(t):# 时间格式转换,将时间戳127转成“08:02:07”形式
t=t+8*60*60
h=t//3600
m=
s=t%60
time='%02d'%h+:'+'%02d%m+:+'%02d'%s
return time
def mov(lst,head):
#更新队伍并输出,代码略
return head
def te(time): #时间格式转换,将“08:02:07”转换成以秒为单位的时间戳127
t=int(time[0:2])*60*60+int(time[3:5])*60+int(time[6:])
t=t-8*60*60 #8 点开始叫号看诊
return t
def insnew(lst,head,data); #将新签到的患者插入候诊队伍中,并更新每个患者预计就诊的时间
data[2]=tc(data[2])
data.append(-1)
p=head;q=p;k=0
if head=-1:# 无人排队
lst.append(data)
else:
while q!=-1 and():
k=k+1
p=q
q=lst[q][3]
data[2]=lst[p][2]+180
data[3]=q
lst.append(data)
lst[p][3]=len(lst)-]
p=len(lst)-1
while q!=-1:
lst[q][2]=1st[p][2]+180
p=q
q=lst[q][3]
return head

①若调用该函数继续存储手机号“180****1215 ”的包裹, 其取件码是“B-0011 ”,则对应 dic[2]的值变为["180****1215", ▲ ,▲]。
②函数 save 代码如下,程序中加框处代码有错,请改正。
def save(pnum,code):
goods.append([code,-1])
n=len(goods)-1
print(n,"号包裹的手机号:",pnum,"取件码:",code)
num=search(dic,pnum) #函数返回手机号 pnum 在 dic 中的索引号,未找到返回-1
if num==-1:
dic.append([pnum,n,1]) #新增一个包裹信息
else:
goods[n][1]=dic[num][1]
dic[num][1]=n
![]()
x=input("请输入您的手机号:")
num=search(dic,x)
if num!=-1:
#输出手机号为 x 的当前所有包裹信息,代码略
op=int(input("输入 0 取全部包裹,输入 1 取部分包裹:"))
if op==0:
print("您的包裹已经取完! ")
del dic[num] #删除 dic 中索引为 num 的元素
else:
order=input("请输入本次的取件码,只输入#表示结束取件:")
while order!="#":
p,q=head,head
while goods[q][0]!=order:
p=q
if p==head:
dic[num][1]=goods[q][1]
else:
goods[p][1]=goods[q][1]
dic[num][2]-=1
if dic[num][2]==0:
print("您的包裹已经取完!")
break
#输出手机号为 x 的当前所有包裹信息,代码略
order=input("请输入本次的取件码, 只输入#表示结束取件:")
else:
print("查无此号,请检查后重新输入!")
def f(a,b):
if a<b:
return a+b
else:
return f(a-b,a+b)
执行语句 x=f(18,-2)后, x 的值为( )
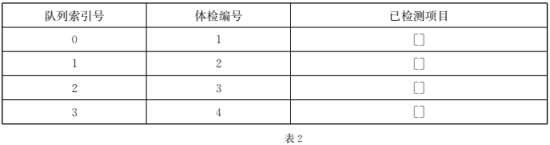
编号登记:为n位体检者设置体检编号1~n。
体检呼叫:体检项目处空闲时呼叫下一个体检者(编号小的优先),若多个项目同时呼叫,体 检者到优先级小的项目处体检。仅考虑常规体检项目,各个项目的优先级及体检时间如表1所示:

前去体检:各个体检项目之间相互独立,互不影响;病人排队体检和体检完毕到下一科室之 间没有时间延迟。
deflst(n):
que=[]

que.append(temp)
return que
若加框处语句改为:
则执行语句lst(4),que的生成结果 (选填:是/否)相同。

Python部分程序如下 , 请在划线处填入合适的代码。
n=10
head=0
que=lst(n)
tail=10
dis=[['B超', 12],[ '心电图' , 5],['抽血', 2],['尿常规' , 2],['C14检测', 2],['胸透' , 2], ['一般常规(身高体重血压)', 1]]
t=[-1]*7 #t记录各个项目当前体检的开始时间
f=[-1]*7 #f记录各个项目当前体检人员编号
def jh(num):
global tail #global能够实现在自定义函数中改变公共变量tail
p=head
while p<tail:
if que[p][0]not in fand num not in que[p][1]: #p体检者等待中且未体检num项目
que[p][1].append(num)
t[num]=time
if len(que[p][1])==7:
temp=que[p]
for i in range(p , tail-1):
que[i]=que[i+1]
que[tail-1]=temp
tail-=1
break
p=p+1
time=0
while tail! =head:
i=0
while i<7:
if t[i]==-1:
jh(i)
elif :
t[i]=-1
f[i]=-1
i-=1
i+=1
time+=1
print('体检完成顺序:')
for i in range( ): #按体检完成顺序输出体检者及其的体检项目顺序
item= que[i][1]
s= ' '
for j in item:
s+=dis[j][0]+'→'
print('编号%d:%s'%(que[i][0], s[:-1]))
2006-2024 深圳市二一教育科技有限责任公司 粤ICP备11039084号 粤教信息(2013)2号
 粤公网安备 44030702000055号
粤公网安备 44030702000055号
邮编:518000 地址:深圳市龙岗区横岗街道横岗社区力嘉路108号B栋B6

 VIP申请
VIP申请
 团体组卷申请
团体组卷申请
